
On April 17, I took the stage at Global Azure Veneto with a dear friend. We share a passion for what we do and for the technology we use every day: he is a Chief Network Architect, and I am a Data Solution Architect. We have different skill sets, often working in separate departments that struggle to communicate with one another.
It is precisely this disconnect that motivated us to create this session together. All too often, those who design data architectures are unfamiliar with the network infrastructure on which they run, and those who design the infrastructure lack full awareness of the requirements of an enterprise data platform. We see the result in projects: network decisions made without considering the serverless pattern, or data architectures designed without knowing how Databricks’ Private Endpoint works. Everyone optimizes their own part, but the system as a whole remains fragile.
We wanted to do the opposite: combine our expertise from the design phase onward, building a complete enterprise architecture where the infrastructure incorporates the needs of the data solution and the data solution relies on a network designed to support it. Preparing this session has been one of the most interesting projects of the past few months. Everyone brought their own expertise to the table, we challenged each other’s ideas, and the final result is better than what we would have produced separately.
What We Discussed
The session was divided into three areas: the Databricks architectural model (Control Plane vs. Compute Plane, Classic vs. Serverless), the latest updates to Unity Catalog in Public Preview, and enterprise network architecture with VNet Injection and NCC.
We began by clarifying a distinction that seems obvious but isn’t in practice: what resides in the Databricks Control Plane (Web Application, Unity Catalog, Compute Orchestration, Queries & Code) and what resides in the customer’s Compute Plane. And above all, the difference between Classic Compute and Serverless Compute, because the two models have completely different networking implications. With Classic Compute, the nodes run in your VNet; you have full control over routing, NSGs, and firewalls. With Serverless, the infrastructure is managed by Databricks; there is no VNet Injection, and the private connectivity model to your data works differently. Starting with this distinction was essential to make sense of everything we demonstrated afterward.
The common thread was the synergy between the two disciplines: a data architecture that is unaware of the network on which it runs is incomplete, and a network designed without considering the needs of serverless compute leaves gaps open at the wrong moment.
Unity Catalog: Model and Latest Updates
We dedicated part of the session to Unity Catalog, starting with the model: the Metastore → Catalog → Schema → Object hierarchy with privilege inheritance, the fine-grained privilege model down to the column and row level, automatic lineage, and integrated auditing. This overview served as a common foundation before diving into the latest features.
The most interesting part was the new features in Public Preview: Governed Tags, Tag Policies with allowed values and assign permissions, and ABAC Policies (Row Filter and Column Mask). I had already written about this in a previous post. During the session, I demonstrated the pattern I use: a governed tag pii for sensitive columns, a Column Mask that uses IS_ACCOUNT_GROUP_MEMBER() to show the actual value only to pii_readers and account_admins, and a Row Filter Policy for business units that restricts row visibility based on the user’s Databricks group. No custom views, no manual scripts.
Classic Compute Architecture: The Details That Matter
On the networking front, we presented the enterprise hub-and-spoke pattern with VNet Injection.
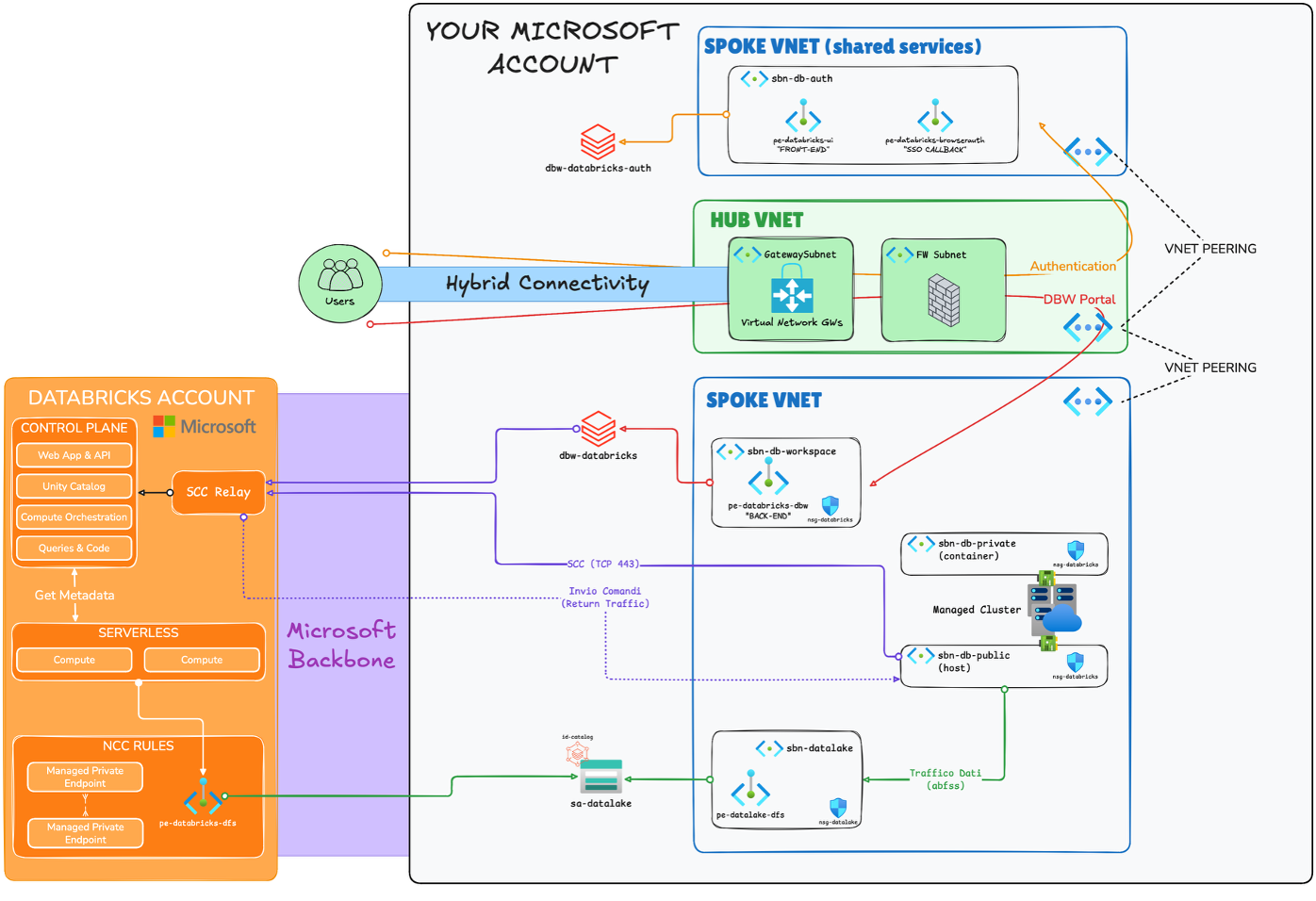
Note on the diagram: We deliberately chose to represent only outbound flows—that is, the direction in which each connection is established. Return traffic travels over the same channel and is implied. Including both directions would have made the diagram confusing and difficult to read, obscuring the architectural patterns I wanted to highlight.
The diagram shows:
- Secure Cluster Connectivity (NPIP) with SCC Relay: clusters do not have public IPs, and the TCP 443 control channel always flows from the data plane to the control plane, not the other way around.
- Back-end private endpoints in the spoke workspace for sub-resource
databricks_ui_api, necessary for the SCC Relay to reach the control plane privately. - Front-end private endpoints in shared services for
databricks_ui_api(user side) andbrowser_authenticationfor the Entra ID SSO callback. - Private endpoints on ADLS Gen2 (
dfs) in the spoke datalake, withabfsstraffic remaining on the Microsoft backbone. - Azure Firewall in the hub with UDR on subnets
hostandcontainerfor outbound traffic, with mandatory FQDN exceptions for Databricks.
One thing I like to focus on whenever I talk about VNet Injection (on Azure Databricks) is subnet naming, because it always causes confusion. Databricks requires two delegated subnets, officially called host and container, but in the documentation and the Azure portal, you’ll also find them listed as public and private. The name public is misleading: it doesn’t mean the nodes have public IPs. With Secure Cluster Connectivity enabled (which is the recommended configuration), no node has public IPs, neither on the host nor in the container.
The distinction is functional, not related to exposure. The host (public) subnet hosts the Spark cluster’s driver node, which coordinates the job, communicates with the control plane via SCC Relay, and interacts with external services. The container (private) subnet hosts the executor/worker nodes, which execute distributed tasks and exchange data with one another. In the past, before NPIP, the driver on the host did indeed have a public IP address to communicate with the control plane. Today, that channel passes through SCC over outbound TCP 443, and the name “public” has remained as a historical legacy. It’s worth explaining this explicitly in the design, because anyone reading a diagram with “public subnet” without context tends to raise an eyebrow.
Serverless and SCC: the pattern that’s often designed poorly
This was the part of the session I cared about most, because it’s where I see flawed architectural designs most often.
When adding Serverless Compute (SQL Warehouse serverless, Jobs serverless, Lakeflow Pipelines) to an architecture already designed for classic clusters, the question is: how does serverless access ADLS Gen2, or Unity Catalog’s managed storage, in a private manner? Serverless isn’t in your VNet. You can’t put a UDR there, and you can’t configure an NSG. VNet Injection doesn’t exist for serverless.
The answer is NCC (Network Connectivity Configuration): a Databricks account-level resource that governs the outbound connectivity of the serverless compute plane. The important part is understanding that NCC has two distinct modes:
- Stable egress IPs: Databricks assigns stable public IPs from which serverless traffic exits. Useful for allowlisting resources that don’t support Private Link, but not useful for true security.
- Private Endpoint Rules: You create an NCC rule pointing to your Azure resource. Databricks provisions Managed Private Endpoints in the serverless compute plane to that resource. You approve the connection request on the Azure side. From that point on, traffic travels over the Microsoft backbone, bypassing the internet.
The correct diagram is not an arrow from the serverless compute plane to the storage account. It is a Managed Private Endpoint in the Databricks serverless compute plane that connects via the Microsoft backbone to your resource, with a connection request approved by you in the Azure portal.
On the same storage account, you can therefore have two private endpoint connections: the one you created (for classic clusters via VNet injection) and the one managed by Databricks via NCC (for serverless). Same resource, two distinct private channels.
What I take away
Presenting these topics is always useful for me. Forcing yourself to build an architectural design that stands up to questions from a technical audience leads you to verify details that you take for granted in your day-to-day work.
What struck me most about the audience’s reactions was how widespread the pattern “I’ll do VNet Injection for classic clusters and add serverless later” still is. “Later” has no design. NCC, PE rules, connection approvals, DNS zones that must also cover UC’s managed storage: these are all elements that must be included in the initial design, not in a subsequent iteration.
Thanks to everyone who attended, and to the organizers of Global Azure Veneto for their careful planning. See you at the next edition.
Resources